on a très souvent besoin de lire ou d’écrire un fichier par programme
notamment bien sûr pour lire les entrées ou sauver les résultatspour la lecture en pratique on utilise souvent des librairies
e.g. pour lire du json ou du yaml, ou des formats spécialiséstoutefois il est bon de savoir utiliser les outils de bas niveau
(enfin, aussi bas niveau que ce qu’offre Python…)
formats et librairies¶
si vous devez lire des formats communs, faites-le avec:
le module standard
jsonpour du JSONla librairie externe
PyYAMLpour du YAMLpandas.read_csv()pour du csvetc...
mais sinon: open() est le point d’entrée¶
lire et écrire un fichier est très facile en Python
ouvrir un fichier pour créer un objet “fichier”
open('mon_fichier.txt', 'r')'r'ouvre le fichier en lecture (défaut),‘w’en écriture,‘a’en écriture à la suite (append),
open()retourne un objet de type fichierqu’il faut bien penser à refermer
sans quoi on provoque des fuites de file descriptors, et au bout
d’un moment l’OS ne nous laisse plus ouvrir de fichiers du tout
utilisez toujours un with¶
c’est pourquoi il est recommandé
de prendre l’habitude de toujours utiliser un context manager
# on n'a pas encore étudié l'instruction with
# mais je vous conseille de toujours procéder comme ceci
# avec with on n'a pas besoin de fermer le fichier
with open('temporaire.txt', 'w') as writer:
for i in 10, 20, 30:
print(f"{i} {i**2}", file=writer)avantage du with:
pas besoin de fermer
même en cas de gros souci (exception)
sans context manager
dans du vieux code, ou du code de débutant, vous pourrez voir parfois ce style; c’est à éviter !
writer = open('temporaire.txt', 'w')
for i in 10, 20, 30:
writer.write(f'{i} {i**2}\n')
writer.close()lecture avec for¶
l’objet fichier est un itérable lui-même
donc on peut l’utiliser dans un
forpour traiter une ligne à la foisc’est *la méthode recommandée pour lire un fichier texte
# pour inspecter ce qu'on vient d'écrire
# dans le fichier qui s'appelle "temporaire.txt"
# dans le répertoire courant
# lire un fichier texte ligne par ligne
# on ne peut pas faire plus compact et lisible !
# remarquez aussi:
# open() sans le mode ⇔ open('r')
with open("temporaire.txt") as reader:
for line in reader:
# attention ici line contient déjà le newline
# c'est pourquoi on demande à print() de ne pas
# en ajouter un second
print(line, end="")10 100
20 400
30 900
lecture en comptant les lignes ?
pour anticiper un peu: si je voulais compter les lignes ?
# ne défigurez pas votre code juste pour avoir un indice de boucle # utilisez enumerate ! with open('temporaire.txt') as reader: # les numéros de ligne commencent à 1 for lineno, line in enumerate(reader, 1): print(f"{lineno}: {line}", end='')
on en reparlera au sujet des itérations...
évitez readlines()
F.readlines()retourne un itérateur sur les lignes
équivalent à itérer sur F directement
mais moins performant (charge tout le fichier !)
et moins pythonique
# ce code fonctionne, mais c'est à éviter # surtout si vous lisez de gros fichiers with open('temporaire.txt', 'r') as in_file: for line in in_file.readlines(): print(line, end='')
autres méthodes en lecture¶
comme toujours, il y a plein d’autres méthodes disponibles sur les fichiers texte, reportez-vous à la documentation pour des besoins spécifiques
fichiers ouverts en binaire¶
ajouter b dans le mode¶
tous les fichiers ne sont pas des fichiers texte
par ex. un exécutable, un fichier dans un format propriétaire
pour ouvrir un fichier en mode binaire:
on ajoute
bau mode d’ouverture,on interagit avec l’objet fichier avec un objet
byteset nonstrc’est-à-dire que la lecture retourne un
bytes
et on ne peut que écrire unbytesil n’y a aucun encodage, décodage,
et aucune conversion de fin de ligne (auberge espagnole)
# pour fabriquer un objet bytes, je peux par exemple
# encoder un texte qui comporte des accents
# (on reparlera des encodages plus tard)
text = "noël en été\n"
binaire = text.encode(encoding="utf-8")
binaireb'no\xc3\xabl en \xc3\xa9t\xc3\xa9\n'# j'ai bien un objet bytes,
# et sa taille correspond au nombre d'octets
# et non pas au nombre de caractères
type(binaire), len(binaire), len(text)(bytes, 15, 12)# remarquez le 'b' dans le mode d'ouverture
with open('temporaire.bin', 'wb') as out_file:
# je peux du coup écrire un objet bytes
out_file.write(binaire)# pareil en lecture, le mode avec un 'b'
# va faire que read() retourne un objet bytes
with open('temporaire.bin', 'rb') as in_file:
binaire2 = in_file.read()# et donc on retombe bien sur nos pieds
binaire2 == binaireTrue# ça aurait été pareil
# si on avait ouvert le fichier en mode texte
# puisque ce qu'on a écrit dans le fichier binaire,
# c'est justement l'encodage en utf-8 d'un texte
# sans le b ici ↓↓↓
with open('temporaire.bin', 'r') as feed:
text2 = feed.read()
text2 == textTruele module pathlib¶
objectifs¶
simplifier la gestion des noms de fichier
pour rendre le code plus concis, et donc plus lisible
notamment, en remplacement de
os.pathqui est old-school (et super vilain)le sous-titre pour
pathlib: object-oriented filesystem paths
présentation du module¶
orienté objet
examiner le contenu du disque existe ou pas, quel type, globbing …
les calculs sur les noms de fichiers
concaténation, suffixes, remonter dans l’arbre …métadonnées
taille, dates de modification, …permet d’ouvrir les fichiers
ne gère pas les urls
en remplacement de ...
pour les anciens, le module pathlib remplace entre autres:
le plus gros de
os.pathcertaines choses de
osglob.globfnmatchenfin il contient un wrapper pour
open()
un exemple¶
orienté objet
le sujet devient plus visible
NB: un objet
Pathest immutable
# savoir si un chemin correspond à un dossier
from pathlib import Path
tmp = Path("temporaire.txt")
if tmp.is_file():
print("c'est un fichier")c'est un fichier
# donc on peut l'ouvrir
with tmp.open() as feed:
for line in feed:
print(line, end="")10 100
20 400
30 900
# on peut faire des calculs sur les noms de fichier
tmp.suffix'.txt'# changer de suffixe
tmp.with_suffix(".py")PosixPath('temporaire.py')# calculer le chemin absolu
# le couper en morceaux, etc...
tmp.absolute().parts('/', '__w', 'slides', 'slides', 'notebooks', 'temporaire.txt')construire un objet Path¶
# un chemin absolu
prefix = Path("/etc")
# le chemin absolu du directory courant
dot = Path.cwd()
# ou du homedir
home = Path.home()
# un nom de ficher
filename = Path("apache")# par exemple le répertoire courant est
dotPosixPath('/__w/slides/slides/notebooks')l’opérateur /¶
un exemple intéressant de surcharge d’opérateur: selon le type de ses opérandes, / fait .. ce qu’il faut ! par exemple ici on ne fait pas une division !
# Path / Path -> Path bien sûr
type(prefix / filename)pathlib.PosixPath# Path / str -> Path
type(prefix / "apache2")pathlib.PosixPath# str / Path -> Path
type("/etc" / Path("apache2"))pathlib.PosixPath# mais bien sûr str / str -> TypeError
try:
"/etc" / "apache2"
except Exception as e:
print("OOPS", e)OOPS unsupported operand type(s) for /: 'str' and 'str'
calculs sur les chemins¶
j’ai créé un petite hiérarchie de fichiers dans le dossier filepath-globbing qui ressemble à ceci
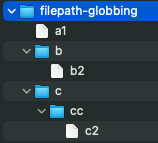
# pour commencer, voilà comment on peut trouver son chemin absolu
globbing = Path("filepath-globbing")
absolute = globbing.absolute()
absolutePosixPath('/__w/slides/slides/notebooks/filepath-globbing')# si on a besoin d'un str, comme toujours il suffit de faire
str(absolute)'/__w/slides/slides/notebooks/filepath-globbing'# les différents morceaux de ce chemin absolu
absolute.parts('/', '__w', 'slides', 'slides', 'notebooks', 'filepath-globbing')# juste le nom du fichier, sans le chemin
absolute.name'filepath-globbing'# le chemin, sans le nom du fichier
absolute.parentPosixPath('/__w/slides/slides/notebooks')# tous les dossiers parent
list(absolute.parents)[PosixPath('/__w/slides/slides/notebooks'),
PosixPath('/__w/slides/slides'),
PosixPath('/__w/slides'),
PosixPath('/__w'),
PosixPath('/')]pattern-matching¶
# est-ce que le nom de mon objet Path
# a une certaine forme ?
absolute.match("**/notebooks/*")Trueabsolute.match("**/*globbing*")Truepattern-matching - dans un dossier¶
# à présent c'est plus intéressant
# avec des chemins relatifs
root = Path("filepath-globbing")
# tous les fichiers / répertoires
# qui sont immédiatement dans le dossier
list(root.glob("*"))[PosixPath('filepath-globbing/c'),
PosixPath('filepath-globbing/a1'),
PosixPath('filepath-globbing/b')]# les fichiers/dossiers immédiatement dans le dossier
# et dont le nom se termine par un chiffre
list(root.glob("*[0-9]"))[PosixPath('filepath-globbing/a1')]pattern-matching - dans tout l’arbre¶
# ce dossier, et les dossiers en dessous
# à n'importe quel étage
list(root.glob("**"))[PosixPath('filepath-globbing'),
PosixPath('filepath-globbing/c'),
PosixPath('filepath-globbing/a1'),
PosixPath('filepath-globbing/b'),
PosixPath('filepath-globbing/b/b2'),
PosixPath('filepath-globbing/c/cc'),
PosixPath('filepath-globbing/c/cc/c2')]# tous les fichiers/dossiers
# dont le nom termine par un chiffre
list(root.glob("**/*[0-9]"))[PosixPath('filepath-globbing/a1'),
PosixPath('filepath-globbing/b/b2'),
PosixPath('filepath-globbing/c/cc/c2')]notions avancées¶
encodages par défaut¶
vous remarquez qu’on a souvent appelé
open()sans préciser l’encodagel’encodage par défaut pour un fichier ouvert en mode texte est celui retourné par
import locale
locale.getpreferredencoding(False)'UTF-8'appeler
open()sans préciser l’encodage peut être risquédépend des réglages sur la machine cible
il vaut mieux toujours être explicite et préciser l’encodage
with open('temporaire.txt', 'r', encoding='utf8') as in_file:
print(in_file.read())10 100
20 400
30 900
le problème est toutefois de moins en moins aigü
Windows, MacOS et Linux à présent configurés par défaut pour UTF-8
si vous avez encore du
cp1252(vieux Windows) ou des ISO-latin15 (Unix)je vous recommande de transcoder tout ça !
fichiers système¶
sys.stdout,sys.stdin,sys.stderrsortie, entrée et erreur standard
accessibles donc au travers du module
sys
import sys
sys.stdout<ipykernel.iostream.OutStream at 0x7f244aede680>