le type bytes¶
non mutable¶
le type
bytescorrespond, comme son nom l’indique, à une séquence d’octets
donc entiers entre 0 et 255le type
bytesest donc un autre exemple de séquence (commestr)c’est également un type non mutable
b = bytes([65, 66, 67])
bb'ABC'# non mutable !
try:
b[1] = 68
except Exception as exc:
print(f"OOPS - {type(exc)}\n{exc}")OOPS - <class 'TypeError'>
'bytes' object does not support item assignment
littéral¶
pour construire un bytes on peut soit
utiliser le constructeur
bytes()- comme slide précédentlire un fichier ouvert en mode binaire - vu plus tard
de manière littérale, mettre un
bdevant une chaîne de caractères
# caractère -> code ASCII
b = b'AB\n'
bb'AB\n'# ou sinon en hexa
b'\x41\x42\x0a'b'AB\n'les détails sordides
comme on le voit dans b'AB\n' , les octets d’un bytes sont parfois représentés par des caractères ASCII
# on peut écrire ceci
b1 = b'ete'
b2 = bytes(
[ord('e'), ord('t'), ord('e')]
)
b1 == b2
-> Truec’est pratique, mais ça peut être source de confusion
car par exemple ceci ne marcherait pas
>>> b'été'
^
SyntaxError: bytes can only contain ASCII literal characters.un bytes est une séquence¶
on manipule des objets
bytespresque comme des objetsstrles bytes sont des séquences (donc indexation, slicing, ...)
essentiellement les mêmes méthodes que pour les
str
# les méthodes dans `str` mais pas dans `bytes`
set(dir(str)) - set(dir(bytes)){'casefold',
'encode',
'format',
'format_map',
'isdecimal',
'isidentifier',
'isnumeric',
'isprintable'}# les méthodes dans `bytes` mais pas dans `str`
set(dir(bytes)) - set(dir(str)){'__buffer__', '__bytes__', 'decode', 'fromhex', 'hex'}texte, binaire et encodage¶
choisir entre
stretbytesquand et comment convertir
codage et décodage en python¶

le problème¶
dès que vous échangez avec l’extérieur, i.e.
Internet (Web, mail, etc.)
stockage (disque dur, clef USB)
terminal ou GUI, etc..
vous devez traiter des flux binaires
et le plus souvent on ne sait pas si/comment le texte a été encodé
notamment crucial en présence d’accents ou autres non-ASCII
et donc vous êtes confrontés à l’encodage des chaines
de multiples encodages¶
au fil du temps on a inventé plein d’encodages
le plus ancien est l’ASCII (années 60!)
puis pour étendre le jeu de caractères
iso-latin-*
cp-1252 (Windows)
et plus récemment, Unicode et notamment UTF-8
aujourd’hui en 2024: UTF-8
privilégier UTF-8 qui devrait être l’encodage par défaut pour tous vos appareils
mais le choix de l’encodage revient toujours en fin de compte au programmeur
même lorsqu’il fait le choix de s’en remettre au paramétrage de l’OS
Unicode¶
codepoints et 3 encodages¶
une liste des caractères
avec chacun un codepoint - un nombre entier unique
de l’ordre de 150.000 + en Unicode-15.1 - sept. 2023l (and counting)
limite théorique 1,114,112 caractères
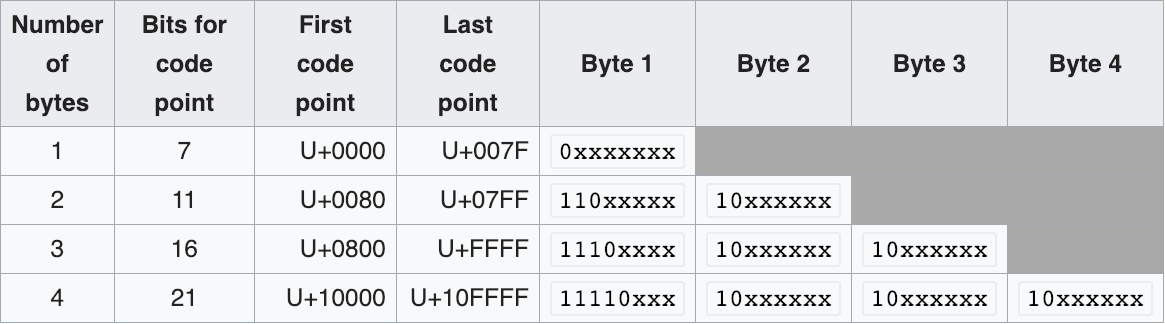
trois encodages:
UTF-8: taille variable 1 à 4 octets, compatible ASCII
UTF-32: taille fixe, 4 octets par caractère
UTF-16: taille variable, 2 ou 4 octets
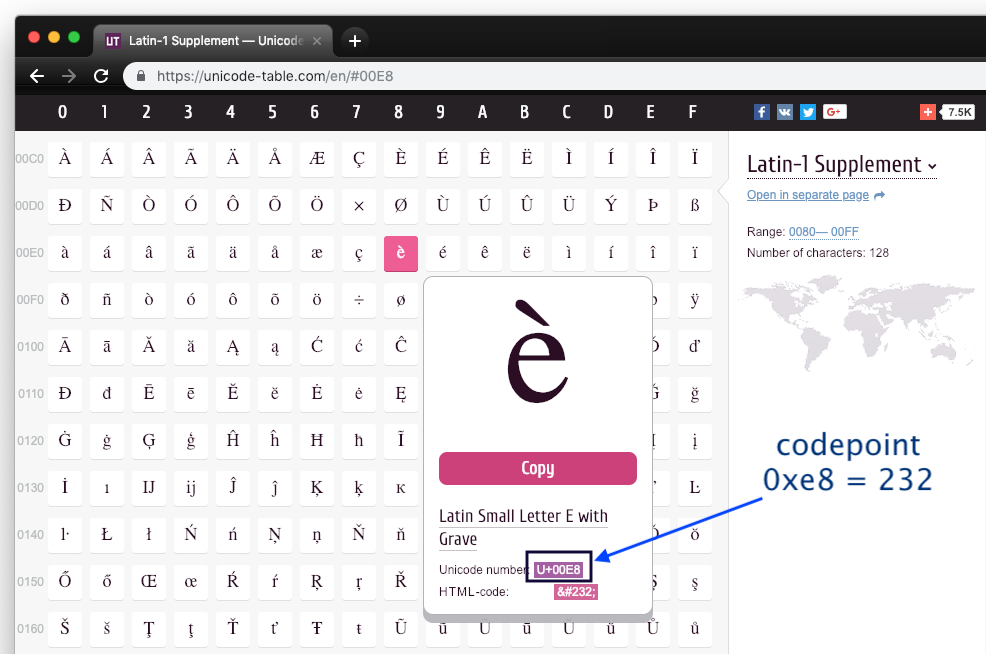
rappels: hexadecimal¶

# an int, entered in hexa, printed in decimal
i1 = 0xe8; i1232# or printed in binary
bin(i1)'0b11101000'# a bytes with one byte
b = b'\xe8'
# and so its only value as an int is
i2 = b[0]
# and there's the same indeed
i1 == i2True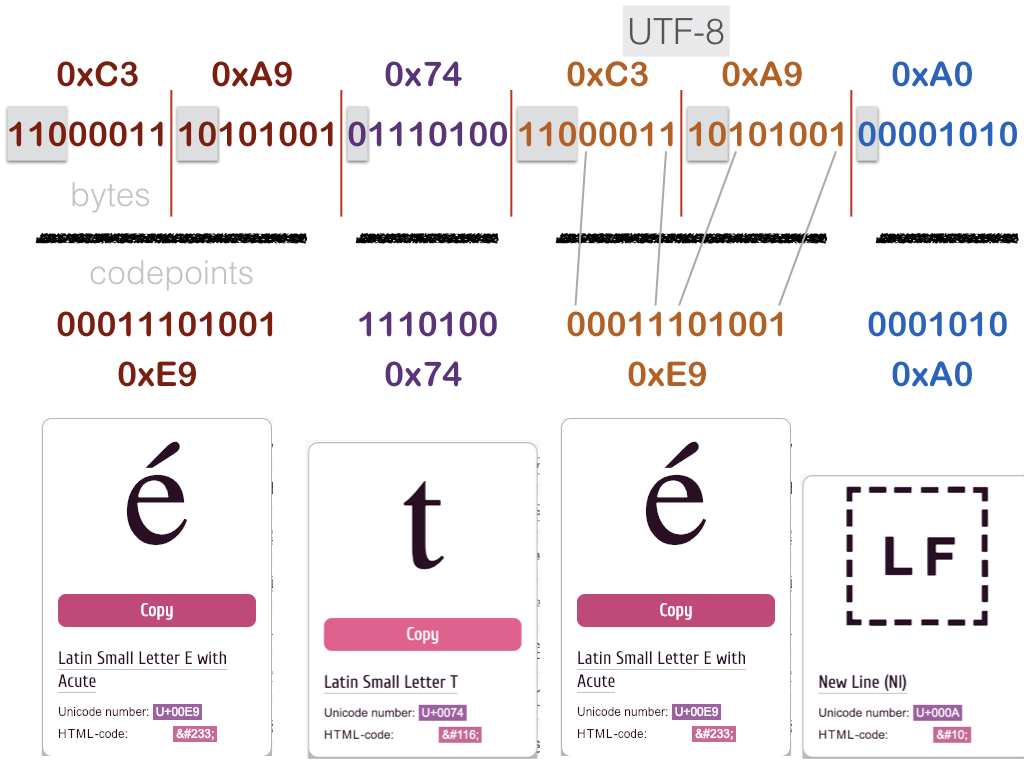
UTF-8¶
le nombre d’octets utilisé pour encoder un caractère dépend
du caractère et de l’encodage
texte ASCII : identique en UTF-8
en particulier, ne prennent qu’un octet
Unicode et Python: chr et ord¶

# le codepoint du é accent aigu
codepoint = 0xe9
codepoint233chr(codepoint)'é'ord('é')233Martine écrit en UTF-8¶

pourquoi l’encodage c’est souvent un souci ?¶
chaque fois qu’une application écrit du texte dans un fichier
elle utilise un encodage
cette information (quel encodage?) est parfois - mais pas toujours - disponible
dans ou avec le fichier
HTTP header - SMTP header
mais le plus souvent on ne peut pas sauver cette information
notamment dans le cas usuel d’un fichier sur le disque dur !
il faudrait des métadata
du coup on utilise le plus souvent des heuristiques
comme d’utiliser une configuration globale de l’ordi
sans parler des polices de caractères..
voyons comment on en arrive par exemple à recevoir un mail en gloubli-goulba
# Jean écrit un mail
envoyé = "Martine écrit en UTF-8"# son OS l'encode pour le faire passer sur le réseau
binaire = envoyé.encode(encoding="utf-8")# Pierre reçoit le binaire mais son ordi
# est un vieux Windows mal configuré
reçu = binaire.decode(encoding="cp1252")# Pierre voit ceci dans son mailer
reçu'Martine écrit en UTF-8'mais le plus souvent ça marche !¶
lorsqu’on travaille toujours sur la même machine,
si toutes les applications utilisent l’encodage de l’OS
tout le monde parle le même encodage
le problème se corse dès qu’il s’agit de données externes
comment en est on arrivé là ?¶
le standard ASCII (1960) définit les 128 premières valeurs
du coup pendant longtemps le modèle mental a été
un char = un octet
cf. le type
charen Cpendant les années 1990 on a introduit un patch
encodages comme
iso-latin1,cp1252préserve l’invariant un char = un octet
au prix .. d’une multitude d’encodages distincts
encodages par défaut¶
# on connait l’encodage du terminal avec
import sys
sys.stdin.encoding'utf-8'# et dans l'autre sens
#
sys.stdout.encoding'UTF-8'# on connait l’encodage du système de fichier avec
sys.getfilesystemencoding()'utf-8'# et le réglage système par défaut
sys.getdefaultencoding()'utf-8'en principe, au 21-ème siècle vous devez avoir utf-8 partout !
partie pour les avancés¶
décodage dégradé¶
pour décoder avec un encodage qui ne supporte pas tous les caractères encodés
decode()accepte un argumenterror"strict"(par défaut)"ignore"(jette le caractère non supporté)"replace"(remplace le caractère non supporté)
octets = 'un été, à noël'.encode(encoding='utf-8')
octets.decode('ascii', errors='ignore')'un t, nol'octets.decode('ascii', errors='replace')'un ��t��, �� no��l'encodage dégradé¶
comment encoder avec un encodage qui ne supporte pas tous les caractères Unicode
encode()accepte un argumenterror, identique i.e.:"strict"(par défaut)"ignore"(jette le caractère non supporté)"replace"(remplace le caractère non supporté)
s = 'un été, à noël'
s.encode('ascii', errors='ignore')b'un t, nol's.encode('ascii', errors='replace')b'un ?t?, ? no?l'Unicode vers ASCII¶
je veux convertir une chaîne Unicode en ASCII en convertissant en caractères proches
dans la librairie standard
unicodedata.normalizeen librairie externe unidecode
pip install unidecode
deviner l’encodage ?¶
formellement : non
en pratique : avec des heuristiques
par exemple avec la librairie externe chardet (voir sur pypi.org)
!pip install chardetCollecting chardet
Downloading chardet-7.4.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl.metadata (9.4 kB)
Downloading chardet-7.4.3-cp314-cp314-manylinux2014_x86_64.manylinux_2_17_x86_64.manylinux_2_28_x86_64.whl (887 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/887.7 kB ? eta -:--:-- ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 887.7/887.7 kB 5.1 MB/s eta 0:00:00
Installing collected packages: chardet
Successfully installed chardet-7.4.3
!chardetect ../data/une-charogne.txt../data/une-charogne.txt: utf-8 with confidence 0.8659807073954984
à savoir : le BOM¶
le
BOM(byte order mark)
est un mécanisme permettant de disambigüer
entre les 3 encodages utf-8, utf-16 et utf-32du coup si vous savez qu’un document est en Unicode
mais sans savoir quel encodage au juste
le BOM permet de le trouver
le BOM consiste à ajouter un header pour utf-16 et utf-32
qui crée une inflation artificielle
# en UTF-32: 1 char = 4 bytes
# donc on devrait voir 4
len("a".encode('utf32'))8# les 4 premiers octets correspondent
# à la constante 'UTF32-LE'
b = "a".encode('utf32')
b[:4]b'\xff\xfe\x00\x00'# évidemment ce n'est ajouté qu'une seule fois
s1000 = 1000*'x'
len(s1000.encode('utf32'))4004petit retour sur le type str¶
les chaines littérales¶
lorsqu’on veut écrire directement dans le programme
une chaine avec des caractères exotiques
# entré directement au clavier
accent = 'é'
accent'é'# copié collé
warn = '⚠'
warn'⚠'# défini à partir de son codepoint
# si petit (un octet), format hexadécimal
'\xe9''é'# si plus grand, utiliser \u
# pour les codepoints sur 2 octets
"\u26A0"'⚠'et enfin, utilisez \Uxxxxxxxx pour 4 octets, si codepoint encore plus grand (pas fréquemment utile)
un exemple¶
s = '\u0534\u06AB\u05E7\u098b\u0bf8\u0f57\u2fb6'
print(s)Դګקঋ௸བྷ⾶
avec ces trois notations '\x \uet\u` il faut bien sûr utiliser exactement, respectivement, 2, 4 ou 8 digits hexadécimaux.
# le retour chariot a pour code ASCII 10
print('\x0a')
# je ne peux pas faire l'économie du 0
try:
print('\xa') # python n'est pas content
except:
import traceback; traceback.print_exc() Cell In[36], line 3
print('\xa') # python n'est pas content
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-2: truncated \xXX escape
le type bytearray (avancé)¶
c’est un objet similaire au type
bytes, mais qui est mutableon l’utilise lorsque l’on a besoin de modifier un objets
bytes
source = b'spam'
buff = bytearray(source)
buffbytearray(b'spam')# remplacer 'a' bar 'e'
buff[2] = ord('e')
buffbytearray(b'spem')for char in buff:
print(char, end=" ")115 112 101 109 méthodes sur bytearray¶
# méthode dans bytes
# mais pas dans bytearray
set(dir(bytes)) - set(dir(bytearray)){'__bytes__', '__getnewargs__'}# méthode dans bytearray
# mais pas dans bytes
set(dir(bytearray)) - set(dir(bytes)){'__alloc__',
'__delitem__',
'__iadd__',
'__imul__',
'__release_buffer__',
'__setitem__',
'append',
'clear',
'copy',
'extend',
'insert',
'pop',
'remove',
'resize',
'reverse'}