pour réutiliser du code en python¶
DRY = don’t repeat yourself : cut’n paste is evil
fonctions | pas d’état après exécution |
modules | garde l’état, une seule instance par programme |
classes | instances multiples, chacune garde l’état, héritage |
programmation orientée objet¶
pourquoi et comment ?
objectif | réutilisabilité, donc |
comment | modularité & héritage (a.k.a. espaces de nom et recherche d’attribut) |
réutilisabilité & modularité¶
une façon d’écrire du code modulaire:
regrouper le code dans une classe et les données dans un objet
de cette façon, la classe constitue un tout cohérent (modularité)
l’encapsulation consiste à séparer l’interface (les méthodes) et l’implémentation
le code qu utilise la classe n’utilise que l’interface
ce qui permet de garantir certains invariants
et de cette façon on se réserve le droit de changer l’implémentation,
sans avoir avoir à modifier le code qui utilise la classe
réutilisabilité & héritage¶
une autre approche consiste à écrire du code générique
par exemple, un moteur de jeu fait “avancer” une collection d’objets
et fournit quelques objets de base, facilement extensibles (grâce à l’héritage)
dès qu’un objet explique comment il avance, il peut faire partie du jeu
dans les deux cas, pour bien comprendre les classes en Python, il faut comprendre deux mécanismes fondamentaux, qui sont
la notion d’espace de nom
et la recherche d’attributs
espaces de nom¶
et pour commencer parlons des espaces de nom:
tous les objets qui sont un module, une classe ou une instance
constituent chacun un espace de nom, i.e. une association attribut → objet
enfin presque
ce n’est pas le cas pour les instances des types natifs, mais bon..
espaces de nom - pourquoi¶
permet de lever l’ambigüité en cas d’homonymie
par ex. si 2 modules utilisent tous les 2 une globale
truc, elles peuvent coexister sans souci
les espaces de nom sont imbriqués (nested) - par ex.
package.module.classe.methodel’héritage rend cela dynamique, i.e. la résolution des attributs est faite à runtime
variables et attributs¶
ce qui nous donne l’occasion d’insister sur ceci; c’est assez basique mais ça va mieux en le disant:

dans l’expression foo.bar.tutu(), il y a une différence fondamentale dans la nature de la variable et des attributs:
la variable est recherchée dans le code du programme; on parlera un peu plus tard de la notion de portée des variables, mais pour faire court on va chercher la variable
food’abord dans la fonction où se trouve ce code (y compris les paramètres), puis si on ne trouve pas dans la fonction englobante, etc.. on parle de liaison lexicale, un terme bien savant qui veut juste dire qu’on peut savoir avec certitude à quoi correspond la variable rien qu’en lisant le programmepar contre, et c’est le point qui nous importe, pour calculer
barà partir de (l’objet référencé par)foo, le calcul est fait à run-time, c’est-à-dire à l’exécution - on parle de liaison dynamique: il faut que l’objetfoosoit un espace de nom, et disons, pour faire simple à ce stade, qu’il contienne l’attributbar; bien entendu le processus est répété pour trouvertutuà partir de (l’objet référencé par)foo.bar
lecture ou écriture des attributs¶
nous allons voir cela en détail tout de suite, et pour cela il nous faut distinguer deux cas
attribut en écriture |
| i.e. à gauche d’une affectation |
attributs en lecture |
| les autres cas |
écriture d’attribut: pas de recherche¶
quand on écrit un attribut dans un objet, le mécanisme est simple:
on écrit directement dans l’espace de nom de l’objet
résolution d’attribut pour la lecture¶
pour la lecture par contre, le mécanisme de résolution des attributs est plus élaboré
fil ournit la mécanique de base de la POO
et sous-tend notamment (mais pas que) la mécanique de l’héritage
lecture: recherche de bas en haut¶
pour la lecture :
la règle pour chercher un attribut en partant d’un objet consiste à
le chercher dans l’espace de nom de l’objet lui-même
sinon dans l’espace de nom de sa classe
sinon dans les super-classes (on verra les détails plus loin)
ex1. de résolution d’attribut¶
# cas simple sans héritage
# appel d'une méthode
import math
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def length(self):
return math.sqrt(self.x**2 + self.y**2)# quand on cherche vector.length
# on cherche
# 1. dans vector - pas trouvé
# 2. dans Vector - bingo
vector = Vector(3, 4)
vector.length()5.0# on va voir ça en détail
# dans pythontutor
%load_ext ipythontutor2 espaces de nom distincts¶
la classe
Vectora les attributs__init__length
l’objet
vectora les attributsxety,mais pas
length!
%%ipythontutor width=1000 height=400 curInstr=7
import math
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def length(self):
return math.sqrt(self.x**2 + self.y**2)
vector = Vector(2, 2)résumé¶
donc dans ce cas simple de la classe Vector et de l’instance vector:
vector.xfait référence à l’attribut posé directement sur l’instancevector.lengthfait référence à la méthode qui est dans la classe
ex2. résolution d’attribut avec héritage¶
jusqu’ici on n’a pas d’héritage puisque pour l’instant on n’a qu’une classe
mais l’héritage est une simple prolongation de cette logique
on verra un peu plus loin la syntaxe pour créer une sous-classe, mais voici déjà un premier exemple simplissime (et un peu bidon du coup)
# ici pour l'instant, une classe fille sans aucun contenu
class SubVector(Vector):
pass
subvector = SubVector(6, 8)
# grâce à l'héritage on peut tout à fait écrire ceci
subvector.length()10.0comment fait-on pour trouver subvector.length ? c’est exactement le même mécanisme qui est à l’oeuvre ! pour évaluer subvector.length(), on cherche l’attribut length
dans l’instance
subvector: nondans sa classe
SubVector: nondans la super-classe
Vector: ok, on prend ça
%%ipythontutor width=1000 height=400 curInstr=8
import math
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def length(self):
return math.sqrt(self.x**2 + self.y**2)
class SubVector(Vector):
pass
subvector = SubVector(6, 8)lecture vs écriture - cas limites¶
(avancé)
il faut se méfier parfois: il y a écriture si et seulement si il y a affectation; du coup dans les deux phrases suivantes, qui semblent pourtant faire la même chose, en réalité la mécanique est totalement différente !
| écriture |
| lecture ! |
alors même que dans les deux cas il y a bien modification des données, évidemment
héritage¶
syntaxe¶
une classe peut hériter d’une (ou plusieurs) autre classes
# la syntaxe est
class Class(Super):
pass
# ou
class Class(Super1, Super2):
passsi A hérite de B, ont dit que
A est une sous-classe de B
et B est la super-classe de A
de ce qui précède:
la sous-classe hérite (des attributs) de sa (ses) super-classe(s)
l’instance hérite de la classe qui la crée
isinstance() et issubclass()¶
isinstance(x, class1)retourneTruesixest une instance declass1ou d’une super classeissubclass(class1, class2)retourneTruesiclass1est une sous-classe declass2
# A est la super-classe
class A:
pass
class B(A):
pass
a, b = A(), B()isinstance(a, A), issubclass(B, A)(True, True)isinstance(b, A), isinstance(a, B)(True, False)# accepte plusieurs types/classes
isinstance(a, (A, B))Truesuper()¶
utile lorsque la spécialisation
consiste à ajouter ou modifier
par rapport à la classe mèrele cas typique est d’ailleurs le constructeur
dès qu’on ajoute un attribut de donnéepermet de ne pas mentionner explicitement
le nom de la classe mère (code + générique)
super() dans le constructeur¶
# illustration de super()
# dans le constructeur
class C:
def __init__(self, x):
print("init x par superclasse")
self.x = x
class D(C):
def __init__(self, x, y):
# initialiser : la classe C
super().__init__(x)
print("init y par classe")
self.y = yc = C(10)init x par superclasse
d = D(100, 200)init x par superclasse
init y par classe
super() dans une méthode standard¶
# super() est souvent rencontrée
# dans __init__ mais s'applique
# partout
class C:
def f(self):
print('f dans C')class D(C):
def f(self):
# remarquez l'absence
# de self !
super().f()
print('f dans D')c = C(); c.f()f dans C
d = D(); d.f()f dans C
f dans D
résumé¶
les instances et classes sont des objets mutables (sauf classes builtin)
chaque instance et chaque classe est un espace de nom
lorsqu’on écrit un attribut, on écrit directement dans l’espace de nom de cet objet
en lecture, on résoud la référence d’un attribut de bas en haut
on utilise
isinstance()pour tester le type d’un objetune méthode peut faire référence à la super-classe avec
super()en général
les classes ont des attributs de type méthode
les objets ont des attributs de type donnée
mais le modèle est flexible, dans le notebook suivant on va voir quelques exceptions notables
annexe: MRO & graphe d’héritage¶
(très avancé)
graphe d’héritage¶
on peut donc construire un graphe d’héritage
allant des super-classes aux instances
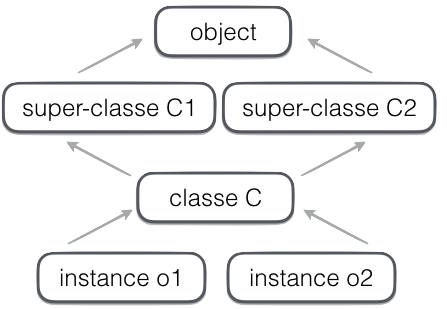
class C1:
pass
class C2:
pass
class C(C1, C2):
def func(self, x):
self.x = 10
o1 = C()
o2 = C()MRO: method resolution order¶
lors de la recherche, si on ne trouve pas dans l’objet ni dans sa classe, il faut décider dans quel ordre on recherche dans les super-classes - pour le cas pathologique où l’attribut serait présent dans plusieurs d’entre elles
on utilise pour cela le MRO : method resolution order; l’algorithme est le suivant
liste toutes les super-classes en utilisant un algorithme DFLR (depth first, left to right)
si classe dupliquée, ne garder que la dernière occurrence
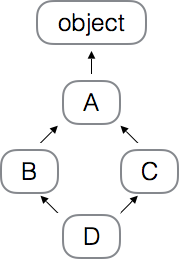
class A: pass
class B(A): pass
class C(A): pass
class D(B, C): passparcours DFLR:
D,B,A,object,C,A,objectsuppressions :
D,B,AobjectC,A,object